draft: true title: “正则表达式回溯问题” date: 2019-07-09T19:12:59+08:00 slug: “” lastmod: 2019-07-09T19:12:59+08:00 keywords: [] description: “” tags: [] categories: [] series: [] author: “heguangfu” katex: true
comment: true
toc: true
autoCollapseToc: true
postMetaInFooter: true
hiddenFromHomePage: false
contentCopyright: “
感谢阅读,如果有问题请您留言,我会及时改正
本博客所有原创文章版权归hgf所有,转载请注明出处hgfkeep.github.io”
reward: false
mathjax: true
mathjaxEnableSingleDollar: true
mathjaxEnableAutoNumber: true
flowchartDiagrams: enable: false options: “”
sequenceDiagrams: enable: false options: “”
typora-root-url: ../../static
发现问题
监控预警CPU占用100%。
- 查看java进程中那个线程造成CPU100%:
top -p<pid> -H, - 依据线程id,生成jstack信息中的nid(n表示native,线程id,十六进制表示):
python -c"print hex(9757)” - dump JVM堆栈,查看造成CPU 100%问题的线程堆栈。
仅排查,发现:
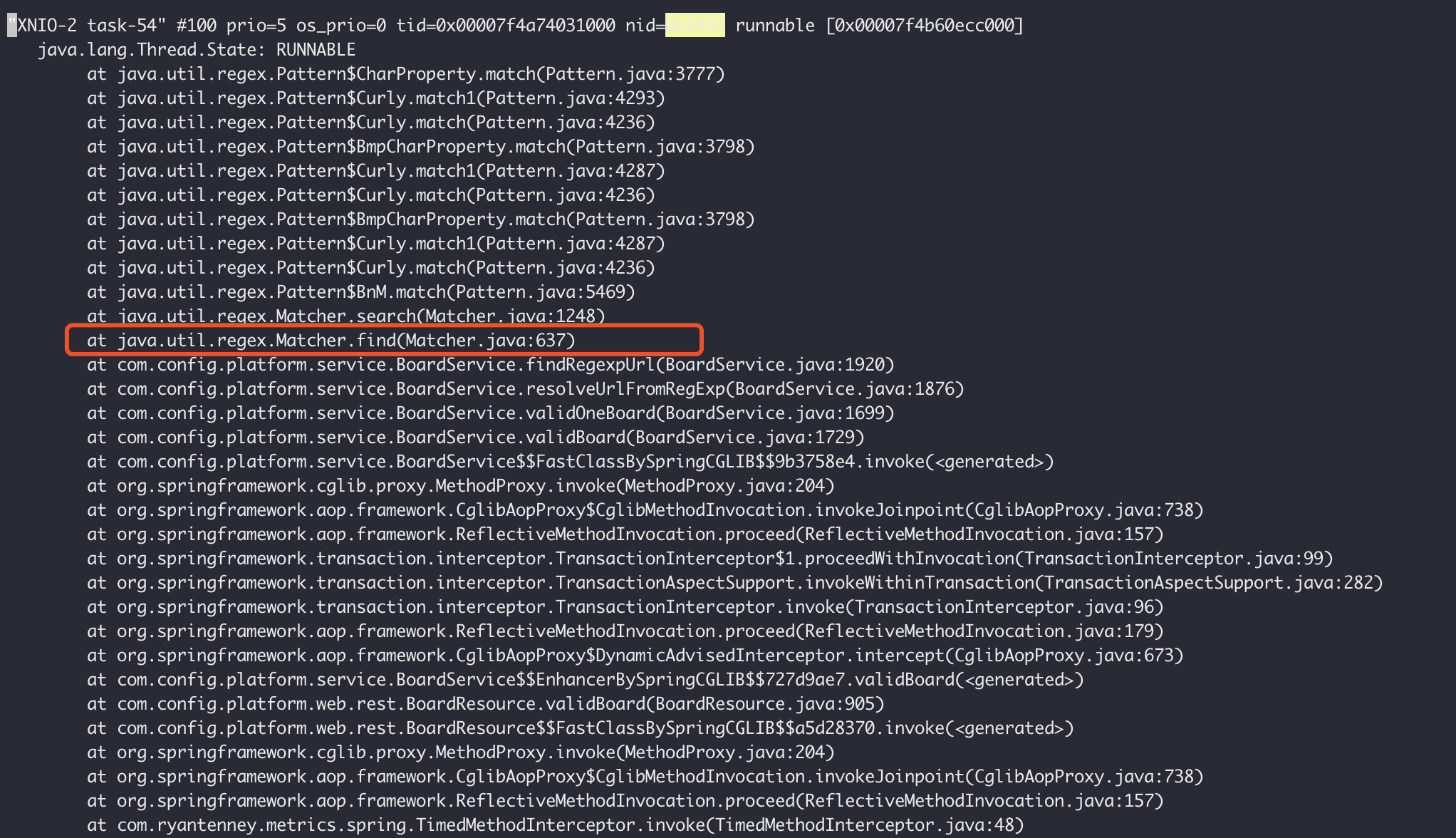
通过查找堆栈信息,发现是正则表达式匹配时,出现了问题。
问题复现
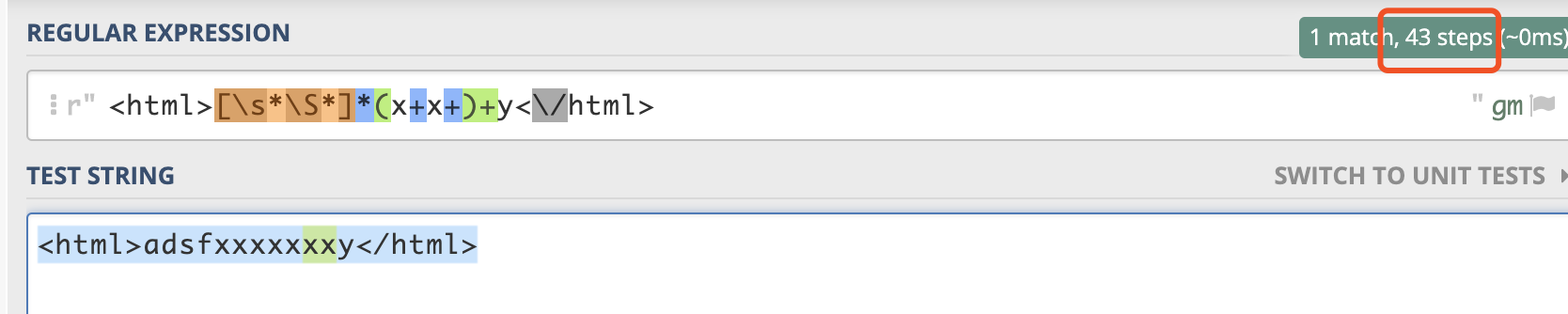
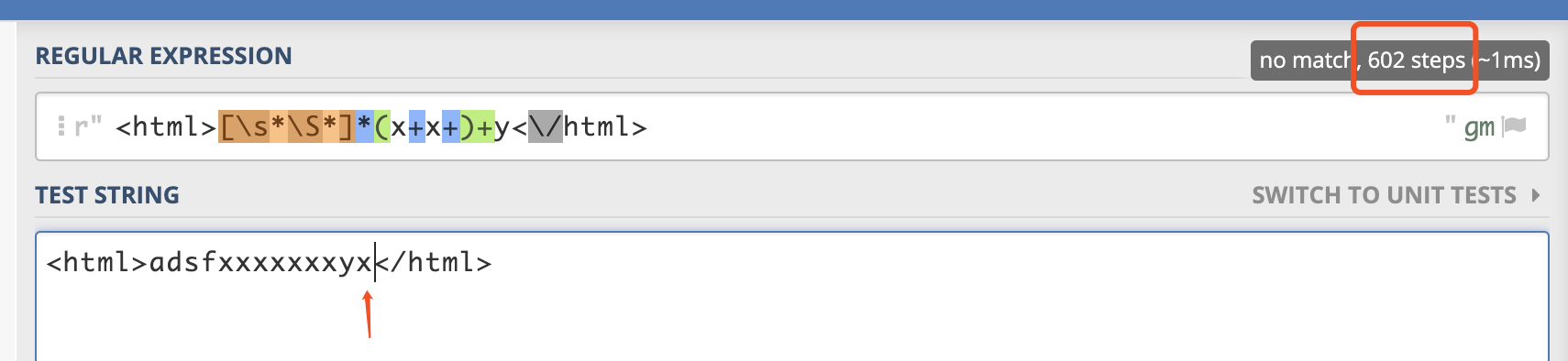
多添加一个异常信息的x,就会造成程序匹配的步数极具增加。且y前面每多一个x,步数就会翻倍。造成计算步数指数级上升。
问题分析
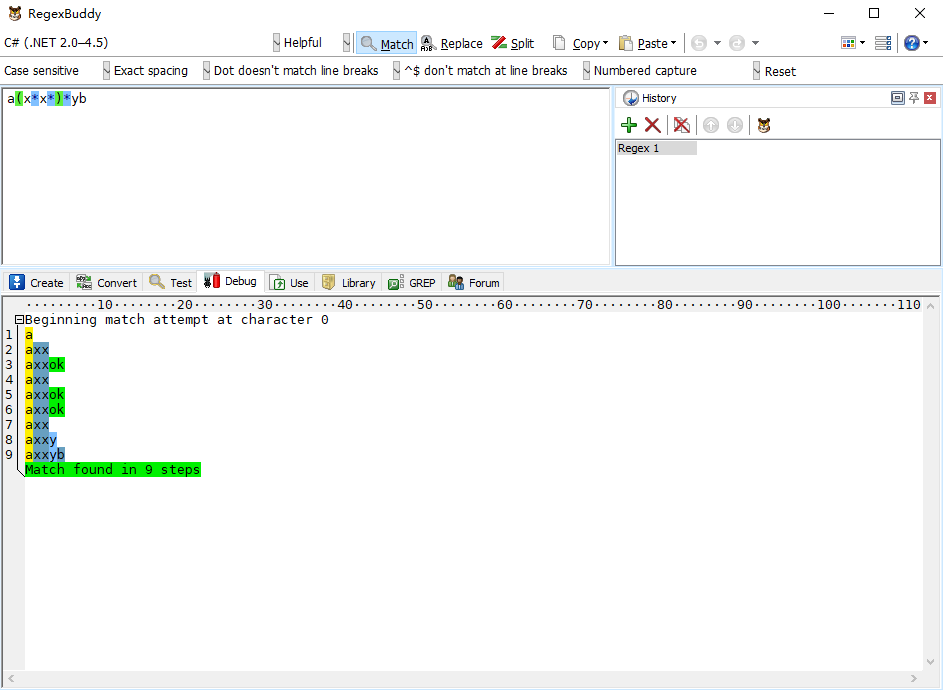
将上述的常量 <html> 和 </html>用简单的字母替换, 例如正则表达式 a(x*x*)*yb, 简单匹配axxyb 需要 9步,如下图:
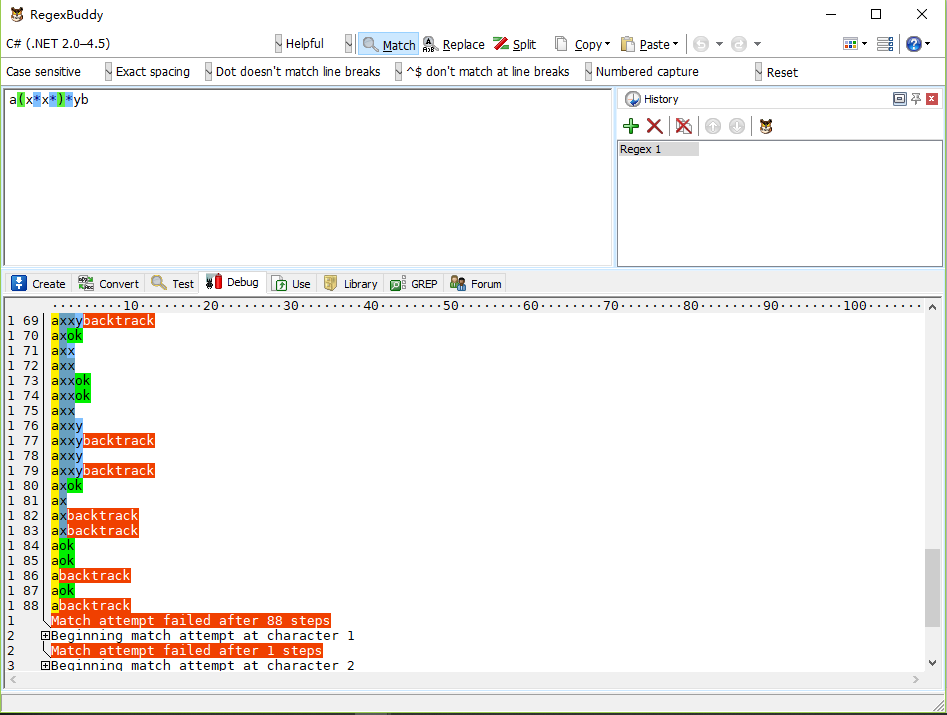
但是待匹配数据无法正确匹配时,如 axxyxb,那么匹配步数变为88步,如下图:
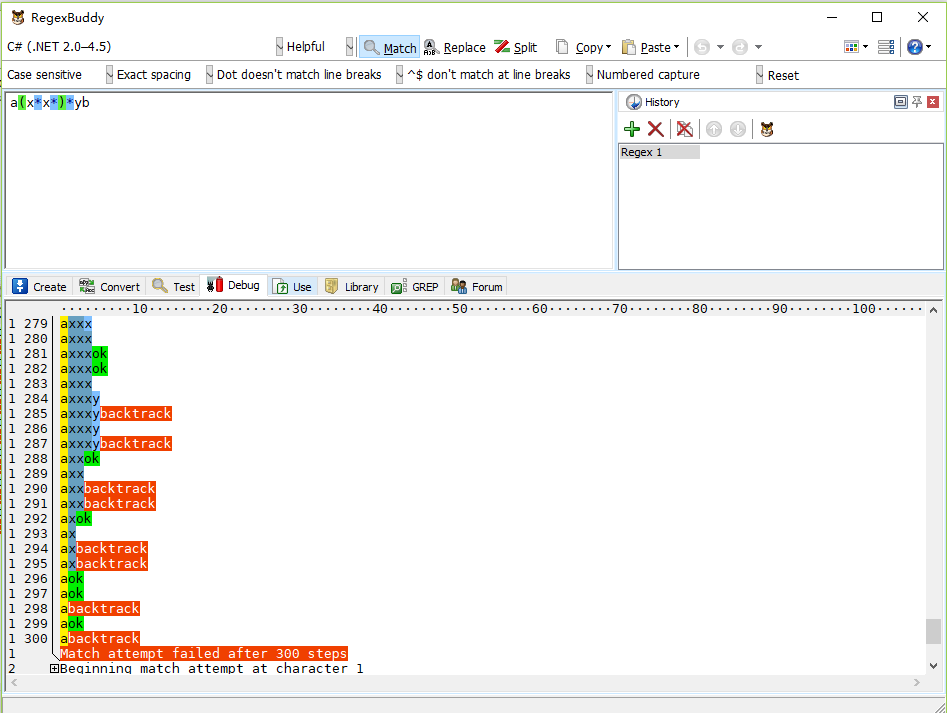
如果需要较长的匹配才能发现无法匹配时,例如待匹配字符串为 axxxyxb 所需步数会更长,如下图:
经过测试,统计结果如下表(正则表达式为 a(x*x*)*yb):
| 字符串 | 匹配步数 | |
|---|---|---|
| axxyb | 9 | |
| axxyxb | 88 | |
| axxxyxb | 300 | |
| axxxxyxb | 1024 | |
| axxxxxyxb | 3496 | |
| axxxxxxyxb | 11936 | |
| axxxxxxxyxb | 40752 | |
| axxxxxxxxyxb | 139136 | |
| axxxxxxxxxyxb | 475040 |
计算步数成指数级上升。可想而知,用正则表达式处理网页信息,会出现占用CPU引起性能问题。
解决办法
- 优化正则表达式
- 有限量词(Possessive Quantifiers)
- 原子分组(Atomic Grouping)
- 避免导致性能问题的回溯:
- 避免前后重复的模式,例如
/x*x*/ - 避免嵌套的量词,例如
/(x*)*/
- 避免前后重复的模式,例如
- 消极方案:如果能查看匹配的步数,那么可以在匹配的步数远大于(例如100倍)待匹配字符串长度时,直接退出。
- 如果能避免用正则去处理上述无法匹配的字符串,也是一种解决方法。