Java性能分析工具
性能分析的前提是将程序的运行状况以及应用的运行环境状况以一种可视化的方式直接的展示出来,那如何实现可视化的展示呢?
本文主要从操作系统提供的工具、java内置的工具和java mission control介绍java性能分析工具。
操作系统工具
操作系统中的工具并非是只针对java的,适合所有程序。
在操作系统中,利用工具收集系统中的各类资源的监控数据,包括:
- CPU
- 内存
- 磁盘
- 网络
只有收集的数据更充分,新能测试的结果才会更准确。
CPU使用率
CPU使用时间分为:
- 用户时间(User Time):CPU执行用户应用程序的时间
- 系统时间(System Time):CPU执行操作系统内核代码的时间。一般与硬件资源打交道,都需要执行内核代码,例如从磁盘读取数据、发送网络请求等。
CPU的调优目标是单位时间内最大限度的提高CPU利用率。
分析思路
在linux操作系统中,执行 vmstat 5, 结果如下:
procs -----------memory--------------- ----swap---- ---io--- -----system------ ----------CPU-------
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 236456 2259632 200052 730348 0 0 1 6 1 1 37 8 55 0 0
2 0 236456 2259624 200052 730348 0 0 0 10 179 332 40 7 53 0 0
2 0 236456 2259624 200052 730348 0 0 0 20 180 356 56 7 37 0 0从输出结果可知,第一次输出的5s内,CPU一共执行 $ (37\% + 8\%) * 5s=2.25s $ ,其中 $37\%$ 执行用户应用程序,$8\%$ 执行系统代码;剩余的 $2.75s$ 处于空闲状态。
一般有三种原因造成CPU闲置:
- 应用程序被线程的同步操作阻塞,直到锁释放。需要合理的减少锁竞争;减少锁的范围
- 应用程序在等待某些请求的响应,例如查询数据。优化请求响应方
- 应用程序无事可做,例如
sleep,等待请求。加大应用程序的负载
java程序和CPU使用率
- 有固定作业量的批处理程序:对于有固定作业量的批处理程序,除非作业全部处理,否则CPU不应该有闲置时间。提高CPU利用率可以加快作业处理效率。
- 接受请求的服务端程序:在没有请求到来,CPU处于闲置状态。当请求到来时,才会利用CPU处理请求。接受请求的服务端程序表现出来的是:特定时间间隔内,CPU利用率较高,其他情况下,CPU利用率较低。此时,可以采取增加程序负载的方式来提升CPU利用率。
多线程池应用程序:
1. **调优多线程程序的目标依然是尽可能的提高每个 CPU 的使用率,使 CPU 尽可能少的被阻塞。**
- 最典型的例子为一个拥有固定大小线程池的应用程序运行数量变化的任务。每个线程每次只能处理一个任务,如果此线程被某些操作阻塞,这个线程不能转而去处理另一个任务。在这种情况下就会出现没有可用线程来处理未完成的任务。因此会导致 CPU 处于闲置状态。
CPU Run Queue
当前可以执行任务的线程数称为run queue。linux中,run queue并长度为当前正在运行和可以运行的线程数,这个长度最小为1;windows中,processor queue并不包括正在运行的线程数,这个数字可以为0。
例如上面的输出中第一行输出的r表示run queue的长度。
磁盘使用率
监控硬盘使用率有两个重要的目标:
- 应用程序本身,如果应用程序进行了非常多的硬盘 I/O 操作,很容易推断出应用程序的性能瓶颈在于 I/O。
- 当应用程序没有高效地使用缓存来进行硬盘写操作时,硬盘 I/O 非常低。
- 当应用程序进行的 I/O 操作数超出了硬盘能够处理的数量,硬盘 I/O 非常高。
- 系统是否在进行交换(swapping)
在linux中执行iostat -xm 5 ,我的结果如下:
avg-CPU: %user %nice %system %iowait %steal %idle
18.20 0.00 40.20 0.00 0.00 51.60
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.20 0.00 34.60 0.10 0.23 8.35 0.00 5.04 0.04 2.02磁盘写入等待时间为5.04ms,磁盘的使用率2.02%, 但是系统执行内核操作用掉了40.02%的时间,这意味着应用程序中存在着低效的写操作。系统每秒进行 $34.60(w/s)$ 次写操作,但是只写入了 $0.23MB(wMB/s)$ 数据。可以判断是IO的性能瓶颈。
再看一组数据:
avg-CPU: %user %nice %system %iowait %steal %idle
40.20 0.00 5.70 49.81 0.00 54.10
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.20 0.00 134.60 0.10 60.45 727.24 68.46 798.04 5.67 100磁盘的利用率100%,等待磁盘的时间(iowait)占到了$49.81%$,应用程序每秒写入 $60.45mb$ 数据,这些数据共同证明 I/O 是应用程序的性能瓶颈所在,必须减少如此大量的 I/O 操作。
vmstat 命令的结果中 si,so 两列数据表示了换入物理内存和换出物理内存的数据量。通过这些数据可以知道系统是否在进行交换。
网络使用率
网络传输类似于硬盘传输,低效地使用网络传输会造成网络带宽不足;如果网络传输的数据量超过了其所能负载的上限同样会造成网络传输性能瓶颈。
操作系统内置的网络监控工具只能获得某个网络接口接收和发送的包数和字节数。通过这些信息还不足以确定网络负载正常还是负载过大。
unix的基本网络工具是netstat。netstat -i 5可以查看网络发送质量。
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
enp2s0f0 1500 39259342994 2 0 0 36119926214 0 0 0 BMRU
enp2s0f1 1500 0 0 0 0 0 0 0 0 BMU
lo 65536 107482004336 0 0 0 107482004336 0 0 0 LRU
virbr0 1500 0 0 0 0 0 0 0 0 BMU
enp2s0f0 1500 39259351171 2 0 0 36119927505 0 0 0 BMRU
enp2s0f1 1500 0 0 0 0 0 0 0 0 BMU
lo 65536 107482004938 0 0 0 107482004938 0 0 0 LRU
virbr0 1500 0 0 0 0 0 0 0 0 BMU其中看网卡enp2s0f0第一次输出(输出结果表示网卡启动后,总共接收/发送的数据包), RX-OK=39259342994表示正确收到了39259342994个数据包, RX-ERR=2表示有2个数据包错误;TX-OK=36119926214表示正确发送了36119926214个数据包。所以,enp2s0f0接收数据包速率 $(39259351171-39259342994)/5=1635p/s$, 接收数据包 $(36119927505 - 36119926214 )/5=258p/s$ ,但是netstat需要通过网络带宽自行计算网络使用率。
nicstat 是unix中使用广泛的第三方网络监控工具,可以得到网络接口的使用率。
nicstat 5 的结果如下:
Time Int rKB/s wKB/s rPk/s wPk/s rAvs wAvs %Util Sat
17:05:17 e1000g1 156.4 256.9 875.0 909.5 215.4 175.3 2.98 0.00可知网络利用率2.98%。
网络传输无法支撑 100%的使用率,在本地以太网网络,超过 40%的使用率就被认为接口饱和。
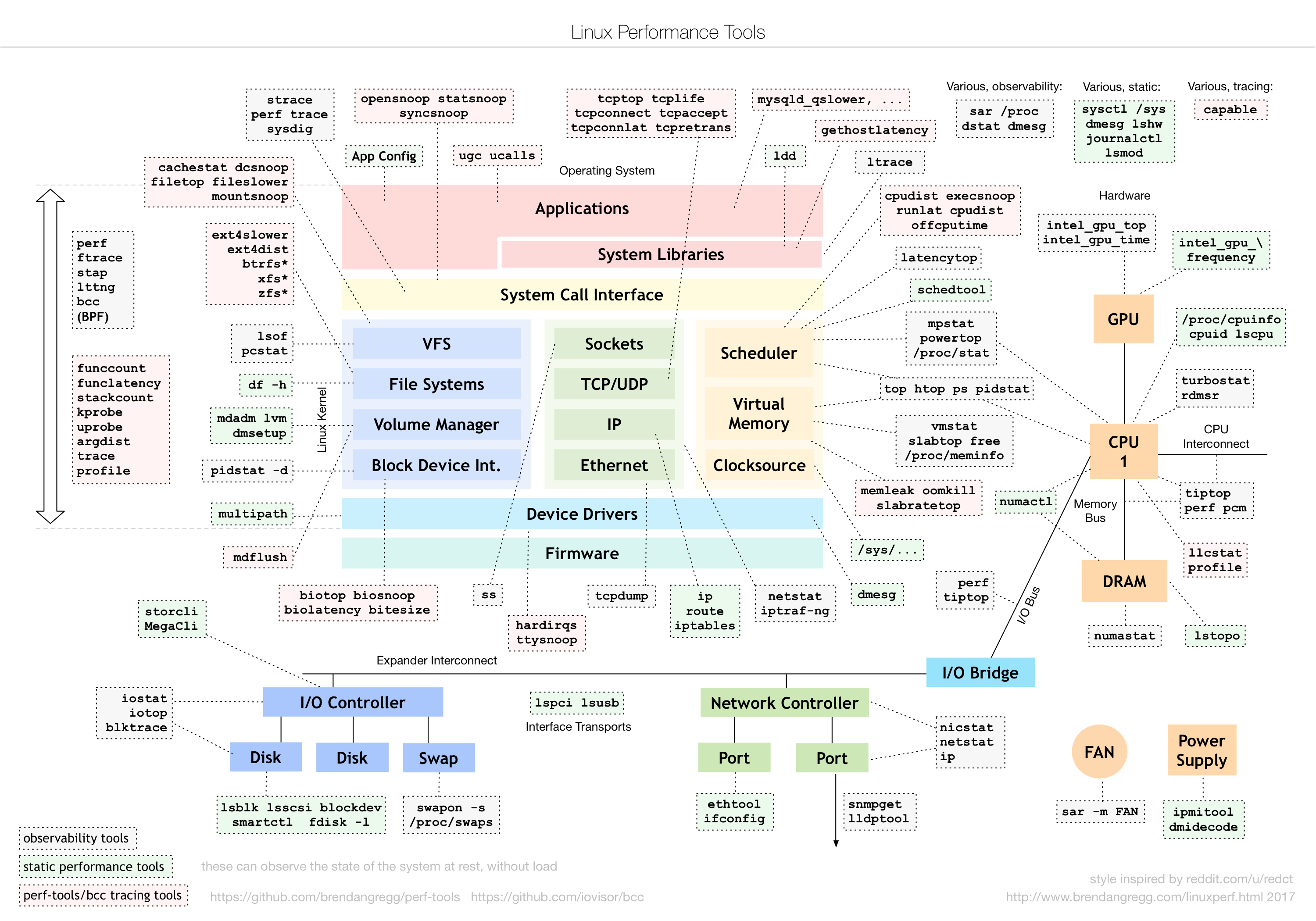
linux系统性能监控工具汇总
java内置工具
- jcmd:打印一个 Java 进程的类,线程以及虚拟机信息。适合用在脚本中。使用 jcmd - h 来查看使用方法。
- jconsole:提供 JVM 活动的图形化展示,包括线程使用,类使用以及垃圾回收(GC)信息。
- jhat:帮助分析内存堆存储。
- jmap:提供 JVM 内存使用信息,适用于脚本中。
- jinfo:访问 JVM 系统属性,同时可以动态修改这些属性。
- jstack:提供 Java 进程内的线程堆栈信息。
- jstat:提供 Java 垃圾回收以及类加载信息。
- jvisualvm:监控 JVM 的可视化工具,剖析运行中的应用程序,分析 JVM 堆存储。
信息角度
JVM 基本信息
- 运行时间:
jcmd <pid> VM.uptime - JVM系统属性:
jcmd <pid> VM.system_propertiesjinfo –sysprops <pid>
- JVM 版本:
jcmd <pid> VM.version - JVM 启动命令:
jcmd <pid> VM.command_line - JVM 调优参数:
jcmd <pid> VM.flags [-all]- jinfo查看某个参数的值:
jinfo -flag <flag_name> <pid>, 例如:jinfo -flag PrintGCDetails <pid> - jinfo 使某个参数生效:
jinfo -flag +<flag_name> <pid>, 例如:jinfo -flag +PrintGCDetails <pid> - jinfo 使某个参数失效:
jinfo -flag -<flag_name> <pid>, 例如:jinfo -flag -PrintGCDetails <pid>
尽管
jinfo命令可以改变任何 flag 的值,但不能确定 JVM 会接受这些改变。例如很多影响垃圾回收算法执行的 flag 都会在 JVM 启动时被设置,在 JVM 运行过程中通过jinfo命令修改 flag 的值并不会影响算法执行。执行命令
java -XX:+PrintFlagsFinal | grep manageable或者jcmd <pid> VM.flags -all|grep manageable可查看可动态修改的flag参数。
线程信息
- JVM栈信息(可明确某个线程是否阻塞):
jstack <pid>jcmd <pid> Thread.print
- jconsole/jvisualvm也可以获取运行中的JVM线程信息。
类信息
jconsole 和 jstat 命令可以获得应用程序运行过程中的所有类的相关信息,同时 jstat 命令也提供了类编译的相关信息。
- 加载的class数量:
jstat -class <pid>,输出的结果含义:- Loaded: 加载的类数量;
- Bytes:加载的类占用的字节数;
- Unloaded:卸载的类数量;
- Bytes: 卸载的类型的字节数;
- Time:类加载和卸载使用的时间,单位
s
- 实时编译的信息:
jstat -compiler <pid>, 输出结果含义:- Compiled:编译数量
- Failed:失败数量
- Invalid:不可用数量
- Time:编译费时,单位s
- FailedType:最近一次编译的方法的编译类型
- FailedMethod:编译失败的方法,包括全限定类和类中的方法。
例如:
$ jstat -class 23935
Loaded Bytes Unloaded Bytes Time
16973 30885.1 0 0.0 26.84加载了16973个类,总共30885.1字节,费时26.84s。
$ jstat -compiler 23935
Compiled Failed Invalid Time FailedType FailedMethod
16175 4 0 208.10 1 com/mysql/jdbc/AbandonedConnectionCleanupThread run垃圾回收相关信息
垃圾回收操作与系统的内存和JVM内存使用情况息息相关,需要使用一下工具监控和调优内存使用。
- Jconsole 展示了 JVM 堆使用的情况,它所绘制的的动态图能够帮助开发人员了解堆的内部情况。
- jmap 提供堆信息总览。
- jmap获取堆内存使用情况:
jmap -heap <pid>
- jmap获取堆内存使用情况:
- jmap获取堆中对象数量和大小:
jmap -histo <pid>- jmap dump堆内存:
jmap -dump:format=b,file=heapdump <pid>(此操作会导致JVM 暂停应用) - jmap 对象finalization信息:
jmap <pid> -finalizerinfo
- jmap dump堆内存:
- jstat 从不同的角度展示垃圾回收是如何工作的。
- 查看垃圾回收情况:
jstat -gcutil <pid> [interval] [counts]
- 查看垃圾回收情况:
- jcmd 支持JFR。
- 创建heap dump:
jcmd <pid> GC.heap_dump filename=<path/to/filename>,与jmap dump操作类似。 - 执行Finalizer:
jcmd <pid> GC.run_finalization相当于System.runFinalization() - 主动GC:
jcmd <pid> GC.run相当于System.gc()
- 创建heap dump:
Heap Dump 文件及其分析
Heap Dump 文件是堆的快照,对于分析内存泄漏和内存优化有重要的作用。
获取heap dump :
- jvisualvm 用户界面可以得到 Heap Dump 文件
jcmd:jcmd <pid> GC.heap_dump filename=<path/to/filename>jmap:jmap -dump:format=b,file=heapdump <pid>
分析heap dump:
- jvisualvm
jhat:jhat <heap_dump_file>。自动解析堆转储文件并启动webserver,默认端口7000
JFR定位性能问题
JFR文件生成参考本文中工具使用角度/jcmd。
工具使用角度
jstat
jstat(JVM Statistics Monitoring Tool)是用于监控虚拟机各种运行状态信息的命令行工具。他可以显示本地或远程虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据,在没有GUI图形的服务器上,它是运行期定位虚拟机性能问题的首选工具。
jstat官方文档地址:https://docs.oracle.com/javase/7/docs/technotes/tools/share/jstat.html
jstat支持的options:
| Option | 说明 |
|---|---|
| class | 类加载器 |
| compiler | JIT |
| gc | GC堆状态 |
| gccapacity | 各区大小 |
| gccause | 最近一次GC统计和原因 |
| gcnew | 新区统计 |
| gcnewcapacity | 新区大小 |
| gcold | 老区统计 |
| gcoldcapacity | 老区大小 |
| gcpermcapacity | 永久区大小 |
| gcutil | GC统计汇总 |
| printcompilation | HotSpot编译统计 |
jmap
jmap是JDK自带的工具软件,主要用于打印指定Java进程(或核心文件、远程调试服务器)的共享对象内存映射或堆内存细节。可以使用jmap生成Heap Dump。
jmap官方文档地址:https://docs.oracle.com/javase/7/docs/technotes/tools/share/jmap.html
内存泄漏检查:
- 先使用
jmap -heap命令查看堆的使用情况,看一下各个堆空间的占用情况; - 使用
jmap -histo:[live]查看堆内存中的对象的情况。如果有大量对象在持续被引用,并没有被释放掉,那就产生了内存泄露,就要结合代码,把不用的对象释放掉。
查看等待fianlizer的对象:jmap <pid> -finalizerinfo
$ jmap -finalizerinfo 2895
Attaching to process ID 2895, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.151-b12
Number of objects pending for finalization: 1JVM会将整个heap的信息dump写入到一个文件,heap如果比较大的话,就会导致这个过程比较耗时,并且执行的过程中为了保证dump的信息是可靠的,所以会暂停应用。
jmap -histo:live这个命令执行,JVM会先触发gc,然后再统计信息。
jhat
jhat用来帮助分析堆转储文件。
jhat <heap_dump_file>。自动解析堆转储文件并启动webserver,默认端口7000比较两个转储文件的变化:
jhat <heap_dump_file> —baseline <exclude_heap_dump_file>
jhat web页面的最下面支持了其他的查询:

jhat还提供了OQL查询语言,OQL语句的执行页面: http://localhost:7000/oql/。
jstack
jstack用于生成java虚拟机当前时刻的线程快照。线程快照是当前java虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。
如果java程序崩溃生成core文件,jstack工具可以用来获得core文件的java stack和native stack的信息,从而可以轻松地知道java程序是如何崩溃和在程序何处发生问题。
用法:
- 获取JVM快照:
jstack <pid>,-l参数可以支持更多的信息。
- jstack处理core文件:
jstack java <core-file>。其中java可能需要知名java文件的路径。-m配置jstack mixed模式,支持处理jvm stack frame和native stack frame。-l参数可以支持更多的信息。
core文件和heap dump文件的区别:
JavaCore文件主要保存的是Java应用各线程在某一时刻的运行的位置,即JVM执行到哪一个类、哪一个方法、哪一个行上。它是一个文本文件,打开后可以看到每一个线程的执行栈,以stack trace的显示。通过对JavaCore文件的分析可以得到应用是否“卡”在某一点上,即在某一点运行的时间太长,例如数据库查询,长期得不到响应,最终导致系统崩溃等情况。
HeapDump文件是一个二进制文件,它保存了某一时刻JVM堆中对象使用情况,这种文件需要相应的工具进行分析,如IBM Heap Analyzer这类工具。这类文件最重要的作用就是分析系统中是否存在内存溢出的情况。
jinfo
用途:
访问 JVM 系统属性,同时可以动态修改部分属性。
可以输出java进程、处理core文件或远程debug服务器的配置信息
用法:
- 打印JVM系统:
jinfo -sysprops <pid> - jinfo查看某个参数的值:
jinfo -flag <flag_name> <pid>, 例如:jinfo -flag PrintGCDetails <pid> - jinfo 使某个参数生效:
jinfo -flag +<flag_name> <pid>, 例如:jinfo -flag +PrintGCDetails <pid> - jinfo 使某个参数失效:
jinfo -flag -<flag_name> <pid>, 例如:jinfo -flag -PrintGCDetails <pid>
尽管
jinfo命令可以改变任何 flag 的值,但不能确定 JVM 会接受这些改变。例如很多影响垃圾回收算法执行的 flag 都会在 JVM 启动时被设置,在 JVM 运行过程中通过jinfo命令修改 flag 的值并不会影响算法执行。执行命令
java -XX:+PrintFlagsFinal | grep manageable或者jcmd <pid> VM.flags -all|grep manageable可查看可动态修改的flag参数。
jcmd
jcmd 打印一个 Java 进程的类,线程以及虚拟机信息。适合用在脚本中。使用 jcmd - h 来查看使用方法。
jcmd的官方地址:https://docs.oracle.com/javase/8/docs/technotes/guides/troubleshoot/tooldescr006.html
jcmd实用程序用于将诊断命令请求发送到JVM,其中这些请求对于控制Java Flight Recordings,排除故障以及诊断JVM和Java应用程序非常有用。它必须在运行JVM的同一台机器上使用,并且具有用于启动JVM的相同有效用户和组标识符。
jcmd的用法是:
jcmd <process id/main class> <command> [options]
其中command的说明如下:
| 命令 | 说明 |
|---|---|
| help | 打印帮助信息,示例:jcmd help [] |
| ManagementAgent.stop | 停止JMX Agent |
| ManagementAgent.start_local | 开启本地JMX Agent |
| ManagementAgent.start | 开启JMX Agent |
| Thread.print | 参数-l打印java.util.concurrent锁信息,相当于:jstack |
| PerfCounter.print | 相当于:jstat -J-Djstat.showUnsupported=true -snap |
| GC.class_histogram | 相当于:jmap -histo |
| GC.heap_dump | 相当于:jmap -dump:format=b,file=xxx.bin |
| GC.run_finalization | 相当于:System.runFinalization() |
| GC.run | 相当于:System.gc() |
| VM.uptime | 参数-date打印当前时间,VM启动到现在的时候,以秒为单位显示 |
| VM.flags | 参数-all输出全部,相当于:jinfo -flags , jinfo -flag |
| VM.system_properties | 相当于:jinfo -sysprops |
| VM.command_line | 相当于:jinfo -sysprops |
| VM.version | 相当于:jinfo -sysprops |
| JFR.start | 启动JFR |
| JFR.stop | 停止JFR |
| JFR.dump | dump JFR |
| JFR.check | 检查JFR状态 |
如果不清楚jcmd支持哪些参数,可以执行:jcmd <pid> help
例如:
$ jcmd 9592 help
9592:
The following commands are available:
JFR.stop
JFR.start
JFR.dump
JFR.check
VM.native_memory
VM.check_commercial_features
VM.unlock_commercial_features
ManagementAgent.stop
ManagementAgent.start_local
ManagementAgent.start
GC.rotate_log
Thread.print
GC.class_stats
GC.class_histogram
GC.heap_dump
GC.run_finalization
GC.run
VM.uptime
VM.flags
VM.system_properties
VM.command_line
VM.version
helpJFR
JFR:Java Flight Record
- 启动JFR:
jcmd <pid> JFR.start name=<name>,启动name=<name>的JFR。 - 检查JFR:
jcmd <pid> JFR.check name=<name>,检查name=<name>的JFR。 - dump JFR:
jcmd <pid> JFR.dump name=<name> filename=<filename>.jfr,dumpname=<name>的JFR。文件后缀必须是jfr. - 停止JFR:
jcmd <pid> JFR.stop name=<name>, 停止name=<name>的JFR。
要使用 JRF 相关的功能,必须使用
VM.unlock_commercial_features参数取消锁定商业功能 。
jconsole
jconsole:提供 JVM 活动的图形化展示,包括线程使用,类使用以及垃圾回收(GC)信息。
IMPORTANT: 可以远程调试的命令(远程地址:[server_id@]<remote server IP or hostname>): jinfo, jmpa, jstack, jstat;支持core文件的命令(命令格式命令 <executable> <core>): jinfo, jmap, jstack